
本文旨在学习Eviews,文本来源于计量经济学实验内容(可点击下载)。
眼前目的:完成计量经济学实验报告
长远目的:为工作……
ps.其实我可能也不从事计量经济学相关工作 🙃
当时学的也很浅,只是当一个学习的过程吧。
Eviews基本操作
数据创建命令
如想建立一个新的工作表可输入命令:CREATE 时间频率类型 起始期 终止期
如建立一个1988年到1999年的年度工作表可利用以下命令:
create a 1988 1999若建立工作表完毕,生成数据类型,可利用data命令
如想建立 y x1 x2 三个变量组成的回归,可利用以下命令:
data y x1 x2若想生成与x1有关联的数据,可利用genr命令
如z1是x1的平方,可利用以下命令:
genr z1=x1^2其他genr命令
genr logx=log(x)
genr z2=1/x2
genr t=@trend(84) (从85年为1开始建立时间变量)
图形分析命令
plot
作用
⑴分析经济变量的发展变化趋势
⑵观察是否存在异常值
变量y的趋势图(曲线图,走势图):
plot y变量 y 与变量 x 的趋势图:
plot y xscat
作用
⑴观察变量之间的相关程度
⑵观察变量之间的相关类型,即为线性相关还是曲线相关,曲线相关时大致是哪种类型的曲线
变量X、Y的相关图(应该就是散点图):
scat x y说明
⑴SCAT命令中,第一个变量为横轴变量,一般取为解释变量;第二个变量为纵轴变量,一般取为被解释变量
⑵SCAT命令每次只能显示两个变量之间的相关图,若模型中含有多个解释变量,可以逐个进行分析
⑶通过改变图形的类型,可以将趋势图转变为相关图
一些英文含义:
Mean——均值 Median——中位数 Maximum——最大值
Minimum——最小值 Std.Dev.——标准差 Skewness——偏度
Kurtosis——峰度 Jarque-Bera—— Probability——概率
Observations——观测值个数
一元回归模型
可利用上述数据创建命令创建工作表,并输入数据
通过曲线图,相关图,分析变量趋势与相关关系。
估计线性回归模型
法一:选择所想分析的数据,右键/as Equation/确保y在第一位/确定,即可进行回归分析
法二:ls 被解释变量 c 解释变量
ls y c x x1 - - -估计非线性回归模型
由相关图分析可知,变量之间是非线性的曲线相关关系。因此,可初步将模型设定为指数函数模型、对数模型和二次函数模型并分别进行估计。
估计非线性回归模型
双对数函数模型:ls log(y) c log(x)
对数函数模型:ls y c log(x)
指数函数模型:ls log(y) c x
二次函数模型:ls y c x x^2
比较模型的经济意义,t检验,拟合优度,进一步分析
多元回归模型
分析有多个数据解释变量的情况
建立包括时间变量的三元线性回归模型
建立数据步骤
⒈建立工作文件: create a 78 94 (建立1978-1994年的数据)
⒉输入统计资料: data y l k (为工作表建立数据)
⒊生成时间变量: genr t=@trend(77) (以77年为0,建立时间变量)
如生产函数 Y:总产值 由三个变量t:时间 L:劳动 K:资本 所影响。
可以在建立数据之后利用最小二乘法进行回归:
ls y c t l k会得出c t l k的回归值,t值,R方值,F值
建立剔除时间变量的二元线性回归模型
命令:
ls y c l k建立非线性回归模型——C-D生产函数
Y = A(t)LαKβμ
genr lny=log(y)
genr lnl=log(l)
genr lnk=log(k)
ls lny c lnl lnk虚拟变量
构造虚拟变量;
方式1:使用DATA命令直接输入;
方式2:使用SMPL和GENR命令直接定义。
data d1
smpl 1 8 #样本期调成1998年其实就是只选中前八个变量
genr d1=0 #把d1 1-8的内容定为0
smpl 9 16 #样本期调成1999年其实就是只选中后八个变量
genr d1=1
smpl 1 16 #调回全部的变量,很重要
genr xd=x*d1
genr xd=x*d1 #建立数据
ls y c x d1 xd #最小二乘多重共线性
多重共线性是指解释变量之间具有高度相关性,不利于回归分析。
检验多重共线性
相关系数检验
create a 78 97
data t x1 x2 x3 x4 x5 #输入数据
cor x1 x2 x3 x4 x5 #或点击View\Correlations由相关系数矩阵可以看出,解释变量之间的相关系数均为0.93以上,即解释变量之间时高度相关的。
辅助回归方程检验
通过建立辅助回归模型来检验多重共线性
ls x1 c x2 x3 x4 x5
ls x2 c x1 x3 x4 x5
ls x3 c x1 x2 x4 x5
ls x4 c x1 x2 x3 x5
ls x5 c x1 x2 x3 x4分析F值的显著,和变量之间的相关关系,当t值大于2时,相关程度大
异方差
正常的回归需要满足同方差性(基本假设),往往现实中会出现异方差的情况,为解决此情况需要进行检验和调整。
检验异方差性
图形分析检验
通过散点图 scat
残差分析
sort x #将数据排序 x:解释变量
ls y x c #建立回归方程排序之后建立回归方程(ls)
view/actual,fitted,residual/residual graph 可得到残差分布图
显示回归方程的残差分布有明显的扩大趋势,即表明存在异方差性
Goldfeld-Quant 检验
将样本安解释变量排序(sort x)并分成两部分,分别得出残差平方和,相除
smpl 1 10
ls y c x #Sum squared resid 残差平方和
smpl 19 28
ls y c xF=RSS1/RSS2 查表F值 相比之后大于则存在异方差性
White 检验
建立回归方程,点击View\residual diagnostic\heter… test\white ,得出nR2,。取显著水平0..05,所以存在异方差性。实际应用中可以直接观察相伴概率p值的大小,若p值较小,则认为存在异方差性。反之,则认为不存在异方差性。
Park 检验
genr lne2=log(resid^2)
genr lnx=log
ls lne2 c lnxlnx的系数估计值不为0且能通过显著性检验,即随即误差项的方差与解释变量存在较强的相关关系,即认为存在异方差性。
Gleiser检验
调整异方差性
确定权数变量
genr w1=1/x^1.6743 #根据Park检验生成权数变量
genr w2=1/x^0.5 #根据Gleiser检验生成权数变量
genr w3=1/abs(resid)
genr w4=1/resid^2利用加权最小二乘法估计模型
在Eviews命令窗口中依次键入命令
ls(w=w1) y c x
ls(w=w2) y c x
ls(w=w3) y c x
ls(w=w4) y c x 对所估计的模型再进行White检验,
对所估计的模型再进行White检验
White检验显示,P值较大,所以接收不存在异方差的原假设,即认为已经消除了回归模型的异方差性
White检验没有显示F值和nR2的值,这表示异方差性已经得到很好的解决
内生解释变量
所谓内生性,是指模型中的解释变量与误差项之间存在相关性,会导致回归不可信,所以要解决。
tnnd,别的都做了,就这个不会还就考这个靠🤬!
一定要找时间把工具变量法写出来。由于我们考的是工具变量法代码表达,所以以下只列举代码公式。
工具变量法使用tsls回归。在EViews中使用工具变量法(TSLS,两阶段最小二乘法)的代码格式与普通最小二乘法(ls)类似,但需要额外指定工具变量。以下是具体语法:
tsls 因变量 常数项 解释变量 @ 工具变量
tsls y c x1 x2 @ c z1 z2 z3序列相关性
回归模型的筛选
分析相关图
相关图表明,
GDP指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而加以比较分析。
scat x y模型估计
ls y c x
genr lny=log(y)
genr lnx=log(x)
genr x2=x^2
ls lny c lnx
ls y c lnx
ls lny c x
ls y c x x2选择模型步骤
- 分析t检验
- 剔除低拟合优度的模型
- 比较各模型的残差分布表
自相关性检验
DW检验
通过计算会得到DW值,通过DW值对dl,du值的比较会得出是否得出存在相关性。(以下表是比较的规则)(DW检验表)
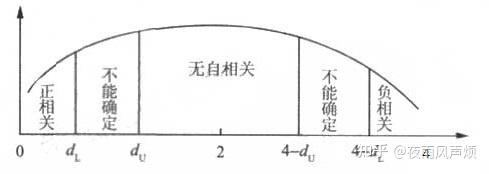
偏相关系数检验
在方程窗口中点击View/Residual Test/Correlogram-Q-statistics
(这个我们好像不考所以不了解)
BG检验
在方程窗口中点击View/Residual Test/Series Correlation LM Test,并选择滞后期为2。
会得到nR2和p值,nR2>5.99则辅助回归方程显著,即存在自相关性。
自相关性的调整:加入AR项
在LS命令中加上AR(1)和AR(2),使用迭代估计法估计模型。键入命令:
ls lny c lnx ar(1) ar(2)之后在进行DW检验和BG检验看看是否有自相关性。具体可参考计量经济学实验内容。
若有错误,请指正。☺️☺️
太厉害了👍
低调(๑•̀ㅁ•́ฅ)